2.11.2. Projections Onto a Hyperplane¶
We can extend projections to \(\mathbb{R}^3\) and still visualize the projection as projecting a vector onto a plane. Here, the column space of matrix \(\bf{A}\) is two 3-dimension vectors, \(\bm{a}_1\) and \(\bm{a}_2\).
The span of two vectors in \(\mathbb{R}^3\) forms a plane. As before, we have an approximation solution to \(\mathbf{A}\,\bm{x} = \bm{b}\), which can be written as \(\mathbf{A}\,\bm{\hat{x}} = \bm{p}\). The error is \(\bm{e} = \bm{b} - \bm{p} = \bm{b} - \mathbf{A}\,\bm{\hat{x}}\). We want to find \(\bm{\hat{x}}\) such that \(\bm{b} - \mathbf{A}\,\bm{\hat{x}}\) is orthogonal to the plane, so again we set the dot products equal to zero.
The left matrix is just \(\mathbf{A}^T\), which is size \(2{\times}3\). The size of \(\bm{\hat{x}}\) is \(2{\times}1\), so the size of \(\mathbf{A}\,\bm{\hat{x}}\), like \(\bm{b}\), is \(3{\times}1\).
As with the vector projection solution of equation (2.27), equation (2.28) minimizes the error for over-determined systems of equations. The orthogonal solution makes use of QR decomposition. When \(\bf{A}\) in equation (2.28) is replaced with \(\mathbf{Q\, R}\), two matrix products reduce to the identity matrix.
Because \(\bf{A}\) is over-determined, the last \(m - n\) rows of \(\bf{R}\) will be all zeros, so we can reduce the size of \(\bf{Q}\) and \(\bf{R}\) with the economy QR option where only the first \(n\) columns of \(\bf{Q}\) are returned. \(\bf{Q}\) is now \(m{\times}n\), and \(\bf{R}\) is \(n{\times}n\). After finding \(\bf{Q}\) and \(\bf{R}\), computing the solution only requires one \(n{\times}m\) multiplication with a \(m{\times}1\) vector and then a \(n{\times}n\) back-substitution of an upper triangular matrix.
In Python, we can find \(\hat{\bm{x}}\) as:
R = scipy.linalg.cholesky(A.T @ A)
x_hat = solve_triangular(R, solve_triangular(R.T, (A.T @ b), lower=True))
# or
Q, R = scipy.linalg.qr(A, mode='economic') # Economy QR
x_hat = scipy.linalg.solve_triangular(R, (Q.T @ b))
The projection vector is then:
The projection matrix is:
Note
\(\bf{A}\) is not a square matrix and thus is not invertible. If it were, \(\mathbf{P} = \bf{I}\) and there would be no need to do the projection. Try to verify why this is the case. Recall that \((\mathbf{BA})^{-1} = \mathbf{A}^{-1}\mathbf{B}^{-1}\).
2.11.2.1. Over-determined Pseudo-inverse¶
Recall from our discussion of square matrices that while we might write the solution to \(\mathbf{A}\,\bm{x} = \bm{b}\) as \(\bm{x} = \mathbf{A}^{-1} \bm{b}\), that is not how we should compute \(\bm{x}\) because computing the matrix inverse is slow. However, a one-time calculation based only on \(\bf{A}\) should be considered when we need to compute multiple solutions with a fixed \(\bf{A}\) matrix and different \(\bm{b}\)’s. We have two ways to achieve this objective that are preferred over computing the inverse of \(\bf{A}\) by elimination. One option is an LU decomposition of \(\bf{A}\) and reuse of \(\bf{L}\) and \(\bf{U}\) with a triangular solver for each \(\bm{b}\). We could also compute the inverse of \(\bf{A}\) from the SVD as shown in Singular Value Decomposition.
Similarly, we sometimes need a one-time calculation on rectangular systems that we can reuse. This is the Moore–Penrose pseudo-inverse of \(\bf{A}\), which we denote as \(\bf{A}^+\), and \(\bm{x} = \mathbf{A}^+ \bm{b}\) is the least squares (minimum length) solution to \(\mathbf{A}\,\bm{x} = \bm{b}\).
We have already found from projections that equation (2.31) is the least squares solution, but it has unacceptable computational performance.
Computing \(\mathbf{A}^{T}\mathbf{A}\) is slow if \(\bf{A}\) is large and the multiplication degrades the condition of the system. Although a solution using the Cholesky solver is reasonable if \(\bf{A}\) is not too large, strategies based on orthogonal matrix factorizations are preferred.
Several matrix multiplications simplify to the identity matrix if we let \(\mathbf{A} = \mathbf{Q\, R}\) or \(\mathbf{A} = \mathbf{U\,\Sigma\,V}^T\) in equation (2.31).
The solutions using the QR and SVD factors in equation (2.32) are
equivalent since computing the pseudo-inverse of \(\bf{R}\) results
in an SVD calculation. By Orthogonally Equivalent Matrices in
Golub–Kahan 1965, matrices \(\bf{A}\) and \(\bf{R}\) are
orthogonally equivalent. So if
\(\mathbf{R}^+ = \mathbf{V\,\Sigma}^+\,\mathbf{U}_r^T\), then
\(\mathbf{A}^+ = \mathbf{V\,\Sigma}^+\,\left(\mathbf{U}_r^T \mathbf{Q}^T\right)\)
is an equivalent equation to \(\mathbf{A}^+\) from the SVD of
\(\bf{A}\) in equation (2.32).
Numerical software uses the SVD to calculate the pseudo-inverses of both
over-determined system and under-determined systems The Preferred Under-determined Solution).
The pseudo-inverse is computed in Python with the command
pinvA = scipy.linalg.pinv(A).
Since \(\bf{\Sigma}\) is a diagonal matrix, its inverse is the reciprocal of the nonzero elements on the diagonal. Refer to equation (4.5) in Properties of Eigenvalues and Eigenvectors. The zero elements remain zero.
In [2]: import numpy as np
In [3]: from scipy.linalg import pinv
In [4]: S = np.diag([2, 3, 0]); print(S)
[[2 0 0]
[0 3 0]
[0 0 0]]
In [5]: print(pinv(S))
[[0.5 0. 0. ]
[0. 0.33333333 0. ]
[0. 0. 0. ]]
Here is an example of using the pseudo-inverse on an over-determined
matrix equation. Note that the full SVD calculation is not needed here.
The economy SVD (full_matrices = False option) is sufficient
(see Economy SVD).
In [1]: import numpy as np
In [2]: from scipy.linalg import svd, qr, solve_triangular, pinv
In [3]: A = np.random.randint(-5, 25, (5, 3)).astype(float)
In [4]: b = np.random.randint(5, 40, (5, 1)).astype(float)
In [5]: Q,R = qr(A, mode='economic')
In [6]: x1 = solve_triangular(R, (Q.T @ b))
In [7]: U,S,Vt = svd(A, full_matrices=False)
In [8]: V = Vt.T # V, not V.T
In [9]: S = np.diag(S) # make S a matrix instead of array
In [10]: Aplus1 = V @ pinv(S) @ U.T
In [11]: x2 = Aplus1 @ b
In [12]: np.allclose(x1, x2)
Out[12]: True
In [13]: x3 = pinv(A) @ b # let pinv do the SVD for us
In [14]: np.allclose(x1, x3)
Out[14]: True
2.11.2.2. Projection Example¶
The projectR3 script and the resulting plot in figure
Fig. 2.24 demonstrate the calculation and display
of a vector’s projection onto the matrix’s column space. The dot product
is also calculated to verify orthogonality.
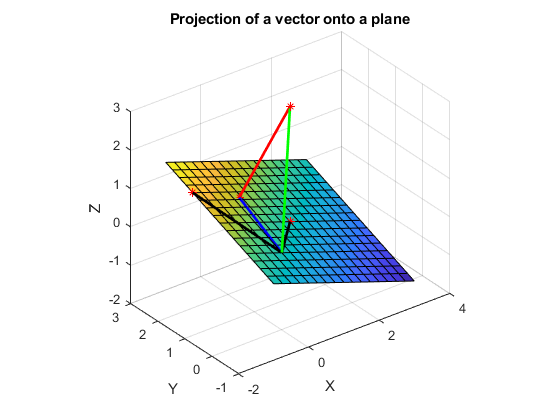
Fig. 2.24 The projection of a vector onto the column space of \(\bf{A}\), which spans a plane in \(\mathbb{R}^3\)¶
# File: projectR3.py
# Projection of the vector B onto the column space of A. Note that with
# three sample points, we can visualize the projection in R^3.
import numpy as np
from scipy.linalg import qr, solve_triangular
a1 = np.array([[1, 1, 0]]).T
a2 = np.array([[-1, 2, 1]]).T
A = np.hstack((a1,a2))
b = np.array([[1, 1, 3]]).T
Q, R = qr(A, mode='economic') # Economy QR
x_hat = solve_triangular(R, (Q.T @ b))
p = A @ x_hat
e = b - p
print(f'Error is orthogonal to the plane if close to zero: {p.T @ e}')
2.11.2.3. Alternate Projection Equation¶
There is an alternate vector projection equation that does not calculate \(\hat{\bm{x}}\). The alternate equation is derived from the QR decomposition, but the \(\bf{R}\) matrix is not used. From equation (2.30), projection from the QR factors is \(\text{proj}_\mathbf{A}\,\bm{b} = \bm{p} = \mathbf{A\, R}^{-1}\,\mathbf{Q}^T\bm{b}\), but \(\mathbf{Q} = \mathbf{A\, R}^{-1}\), so \(\text{proj}_\mathbf{A}\,\bm{b} = \mathbf{Q\,Q}^T \bm{b}\). However, note that this form of the projection equation is only applicable when \(\bf{A}\) is over-determined, and the economy QR decomposition is used because when \(\bf{Q}\) is square, then \(\mathbf{Q\, Q}^T = \mathbf{I}\). So, more generally, we write the projection equation as the sum of the projections of \(\bm{b}\) onto each orthogonal basis vector.
Let \(\mathbf{Q} = \{ \bm{q}_1, \bm{q}_2, \ldots , \bm{q}_n \}\) be an
orthonormal basis for the column space of matrix \(\bf{A}\). The
basis vectors may be found using either QR decomposition
(QR Decomposition), the Gram–Schmidt process (Finding Orthogonal Basis Vectors), or the economy SVD
method (Projection and the Economy SVD), which is used by the scipy.linalg.orth function.
Then the projection of vector \(\bm{b}\) onto
\(\text{Col}( \mathbf{A} )\) is defined by sums of scalar–vector
multiplications.
The alternate equation provides additional observations about the geometry of projection.
Any vector in the vector space must be a linear combination of the orthonormal basis vectors.
The \(\bm{b}^T \bm{u}_i\) coefficients in the sum are scalars from the dot products of \(\bm{b}\) and each basis vector. Since the basis vectors are of unit length, each term in the sum is \(\left(\norm{\bm{b}}\,\cos(\theta_i)\right)\,\bm{u}_i\), where \(\theta_i\) is the angle between \(\bm{b}\) and the basis vector. Thus, each term in the sum is the projection of \(\bm{b}\) onto a basis vector.
Note
Use equation (2.33) when each \(\bm{q}_i\) is unit length, but divide each term by the dot product of \(\bm{q}_i\) (\(\bm{q}_i^T \bm{q}_i\)) when they are not unit length.
The altProject script finds the projection using the two
methods.
# File: alt_project.py
# Comparison of two alternate projection equations
# Define the column space of A, which forms a plane in R^3.
import numpy as np
from scipy.linalg import qr, cholesky, solve_triangular
a1 = np.array([[1, 1 ,0]]).T
a2 = np.array([[-1, 2, 1]]).T
A = np.hstack((a1, a2))
b = np.array([[1, 1, 3]]).T
# Projection onto the column space of matrix A.
R = cholesky(A.T @ A)
x_hat = solve_triangular(R, solve_triangular(R.T, (A.T @ b), lower=True))
p = A @ x_hat
print('Projection onto column space: ')
print(p)
# Alternate projection
# The projection is the vector sum of projections onto the orthonormal
# basis vectors of the column space of A. Note the use of both
# inner product multiplication (``@``) and scalar to vector
# multiplication (``*``).
Q,_ = qr(A, mode='economic')
q1 = Q[:,[0]]
q2 = Q[:,[1]]
p_alt = b.T @ q1 * q1 + b.T @ q2 * q2
print('Projection onto basis vectors: ')
print(p_alt)
The output from the vector projection example follows.
Projection onto column space:
[[0.18181818]
[1.81818182]
[0.54545455]]
Projection onto basis vectors:
[[0.18181818]
[1.81818182]
[0.54545455]]
2.11.2.4. Higher Dimension Projection¶
If the matrix \(\bf{A}\) is larger than \(3{\times}2\), then we can not visually plot a projection as we did above. However, the equations still hold. One of the nice things about linear algebra is that we can visually see what happens when the vectors are in \(\mathbb{R}^2\) or \(\mathbb{R}^3\), but higher dimensions are fine, too. The projection equations are used in least squares regression, where we want as many rows of data as possible to fit an equation to the data accurately.
